
Schema Search MCP Server
Published:
Schema Search is an MCP server that allows you to query large relational schemas with plain language. It builds schematic embeddings straight from your database metadata without vector database dependencies, and in milliseconds.
Why I built it
- Day-to-day DB questions like “where do we store refunds?” shouldn’t take 20 minutes of grep.
- LLMs struggle with 10+ table schemas unless you hand them carefully curated subsets.
- Institutional knowledge about db schemas gets lost over time.
Key features
- Hybrid, semantic, BM25, and fuzzy search with or without reranking,
- Configurable hops across foreign keys and option to summarize schema with llms.
- Automatic index refresh when schemas change; caches stay in sync with reality.
- Embeddings live in memory by default, keeping the footprint small even past 1,000 tables.
Installation
Install with uv or pip:
uv pip install "schema-search[postgres,mcp]"
# or
pip install "schema-search[postgres,mcp]"
Use
Drop it into Claude Desktop (or any MCP client) by adding:
{
"mcpServers": {
"schema-search": {
"command": "uvx",
"args": [
"schema-search[postgres,mcp]",
"postgresql://user:pass@localhost/db",
"path/to/config.yml"
]
}
}
}
Use the CLI to point at any supported RDBMS:
schema-search "postgresql://user:pass@localhost/db" "path/to/config.yml"
Performance
Two quick benchmarks from the Spider dataset highlight the low-latency indexing and hybrid accuracy:
Without reranker:
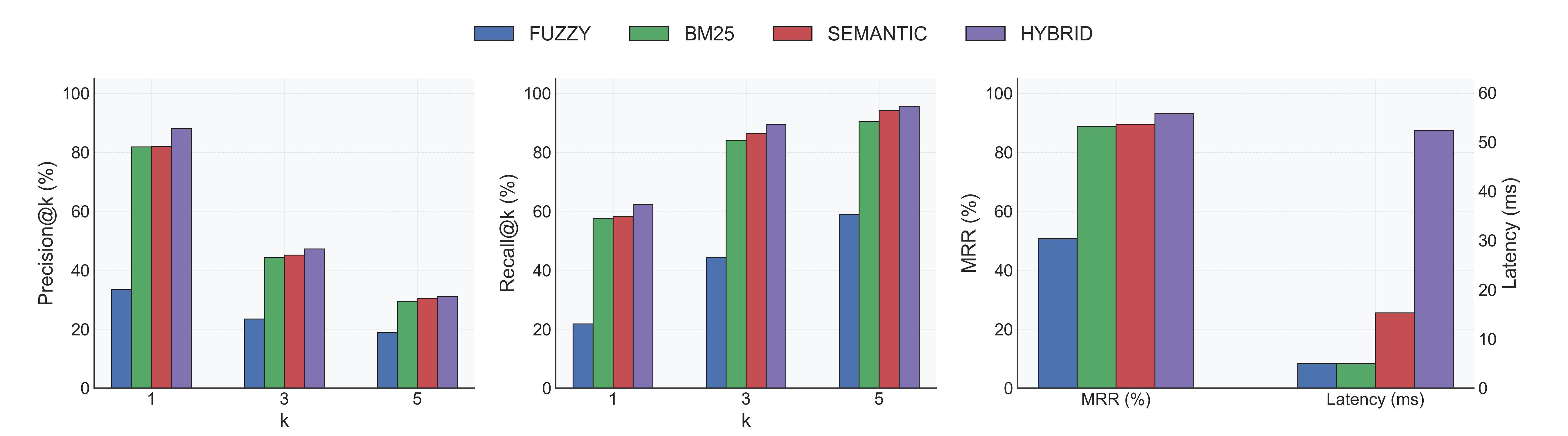
With reranker:
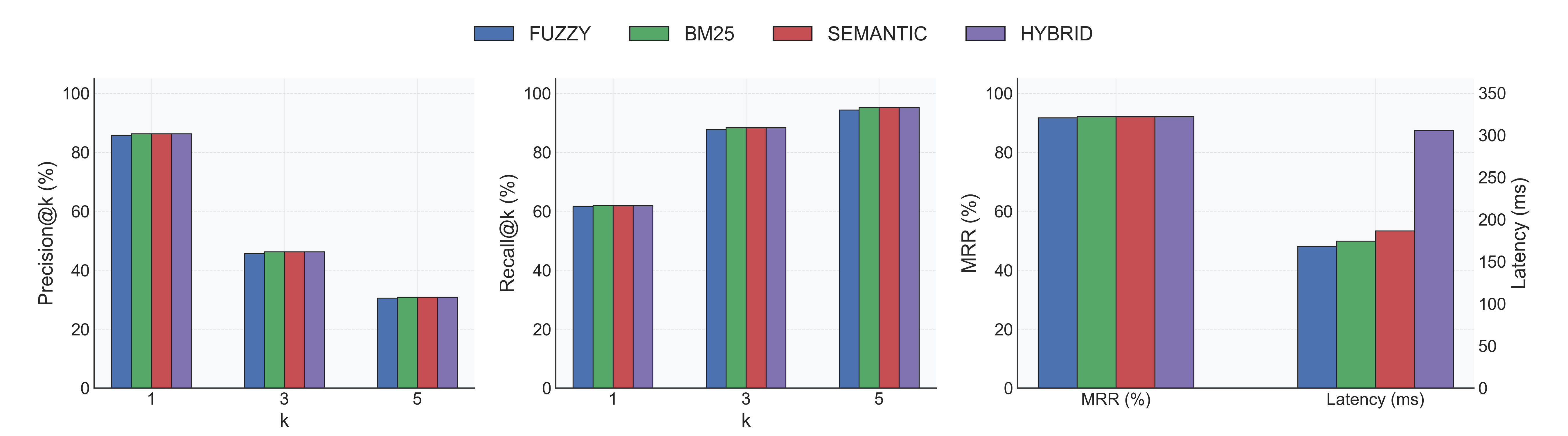
Find the source, config templates, and integration examples on GitHub: Neehan/schema-search.